Scrape the web for football play-by-play data, part 3
This is part three, the fourth is a series of articles about scraping college football play-by-play data from the web. You can check out part one, part 1.5, and part two.
##What’s New The scripts have been cleaned up and I’ve fixed bugs. Also, I made some executive decisions about how to code data in order to get consistent results. For example, the kicking team on a kickoff is now defined to have possession for that play, and kickoffs are linked to the ensuing drive. Most of the improvements are minor and can help handle differences in the way that scorekeepers enter the play-by-play.
##R package pbp
The big news is that I’ve collected the code into an R package and hosted it on Github. You can install it using Hadley Wickham’s devtools package like so:
library(devtools)
install_github("wrbrooks/pbp")###Function parse.url
The main function in the pbp package is called parse.url. It takes as its only argument a url string, which should point to the complete (Make sure you select “All” quarters!) ESPN play-by-play for the game you want to analyze. The function returns a large data.frame with one row for each play in the game. For example, here I’ll load the play-by-play from the national championship game between Ohio State and Oregon:
url = "http://espn.go.com/ncf/playbyplay?gameId=400610325&period=0"
plays = parse.url(url)Now, to plot the scoring margin as the game progressed:
plays %>% ggplot + aes(x=3600-time, y=score.home - score.away) +
geom_line() + ylab("OSU lead") +
xlab("Seconds of elapsed game time")Produces the plot:
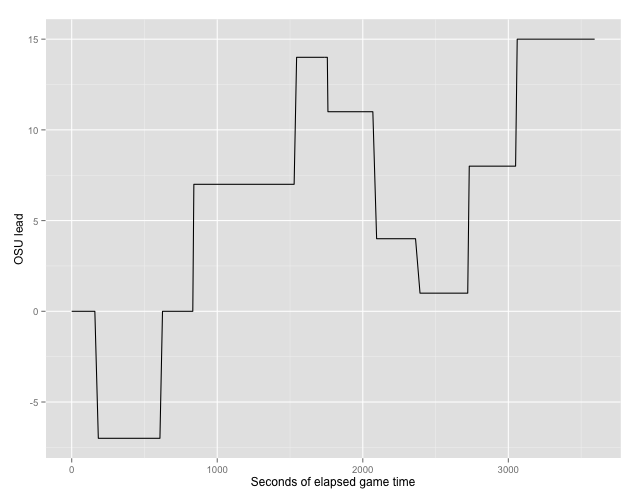
###Outstanding issues
Documentation is the obvious one - package pbp has definitely earned its v0.1 status! The code is kind of brittle and can barf when a scorekeeper does something unexpected (or when it encounters a weird game situation). It would be nice if this code could work for NFL play-by-play too, but their scorekeepers have different standards and I haven’t yet made my regexes flexible enough to handle either league.
Enjoy, hack away, and feel free to submit pull requests on Github when you have improved the code. Thanks!